2011/12/09(金)Alexaのグラフで4年前までのデータを取得できた。
2011/12/09 14:24
例)
r=に期間を指定。u=でドメインを指定。
6ヶ月
http://traffic.alexa.com/graph?r=6m&u=twitter.com
52ヶ月
http://traffic.alexa.com/graph?r=52m&u=twitter.com
せっかくなのでCeronのサイト情報ページには52ヶ月を貼っておくことにしたよ!
http://ceron.jp/site/twitter.com
Ceronのサイト情報ページは
http://ceron.jp/site/<ドメイン>
で見られます。
2011/12/08(木)オープンソースの全文検索エンジンSolrについてメモ
2011/12/08 13:19
Solrってのがなんか良さそうだったのでインストールしたりしてみた。
オープンソースの全文検索エンジンにはいろいろあって、有名なのはNAMAZUとかSenna。
NAMAZUは小中規模向けっぽい。
SennaはMySQLを置き換える格好になるのでちょっと使いたくないなと思ってた。
で、Solrは単独で機能する上にかなり大規模までいけるらしい。20億インデクスくらいいけるとどっかに書いてあった。
ちなみにエンジンのコアはLuceneというやつで、それにいろいろくっつけて便利にしたのがSolr。さらにGUIとクローラーまでくっつけたFessというのもあって、これは日本人が作ってたりする。クローラー付きのものにはNutchという海外産のものもある。
でもどれも全体的にドキュメントが少ない。今回試してみたけど、結局よくわからん部分も多く、実戦投入まではいきませんでした。Ceronの全文検索とかまかせられればよかったんだけど。
Nutchは「Googleに代わるオープンな検索エンジン」を標榜してたりするので、サイト内検索とかじゃなくネット全体の検索エンジンも作れそうな気もするけど実際のところ負荷的にどうなんですかね。期待もあるけど気軽に試すレベルでもないしなあ。20億インデクスじゃ足らなそうだけど。
で、以下、Solrをインストールして稼働させるまでに調べたことを備忘録でメモしておきます。ご参考まで。殴り書きですすいません。
・基本、ダウンロードして解凍するだけ。お手軽。
・サーバにサービスとして認識させるために起動シェルを登録。
http://ochien.seesaa.net/article/153105901.html
http://d.hatena.ne.jp/fat47/20110920/1316505461
init.dまわりの説明はこちら http://www.usupi.org/sysad/031.html
・そのままだと日本語対応してないので形態素解析とか入れる。
以前はSenが主流だったけど開発終了。いまは日本語検索にはGoSenを使うらしい。
http://d.hatena.ne.jp/lettas0726/20110711/1310375789
http://d.hatena.ne.jp/hjym_u/20110620/1308578328
・速度的にもSolr優秀。Sennaより成績いい。
http://thinkit.co.jp/book/2008/11/25/211
・PerlインタフェースとしてWebService::Solrがある。
けど、ちょっと巨大すぎ?依存モジュールがやたら多い。自作したほうがよさげ。
・基本マルチコアにする。
各コアにlibディレクトリを作り、それぞれに日本語トークナイザーを入れる。
・Solr自体がWebサーバ(jetty)を持ってて管理画面はその上で動く。Apacheと連携させちゃったほうが管理面で何かと便利そう。
http://www.atmarkit.co.jp/fjava/rensai4/safetomcat_01/safetomcat_01_2.html(理屈はここの中盤のTomcatの場合と同じ)
→でもなんかうまくいかなかった!!!未解決!
以上。
追記(2011/12/9)
ちなみに本は下記を買いました。これ一冊で基本的な部分は困らない。

Apache Solr入門
追記(2012/6/17)
ログの出力先の設定がググっても出てこなくて迷ったが、上記起動シェル内で設定していた。これで/var/log/以下にsolr.logが出てくるので、logrotate.dでログローテーションの設定をすればいい感じになる。
2011/12/06(火)レビューとレコメンドの総合サイト「フルチェック」をはじめました。
2011/12/06 11:04
レビューとレコメンドの総合サイト「フルチェック」
http://flck.jp/
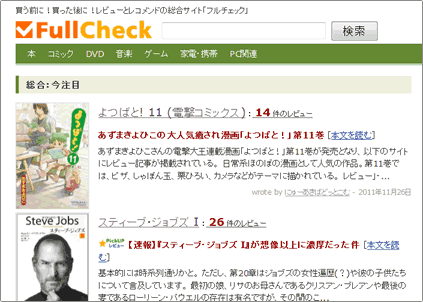
ネット上のさまざまなサイトやブログで書かれたレビューを集約したレビューまとめサイトです。また、同様にネット上のさまざまなデータを分析して、商品同士の関連性を計算したレコメンド機能も提供する予定です。
3年ほど前から似たようなコンセプトでブロガーの本棚という書評まとめサイトを運営していますが、これを本だけに限らず拡大、充実させるような形を目指しています。ブロガーの本棚はそれなりに好評価をいただきながらもアクセス数的にはいまいち伸びなかったので仕切り直し、という意味もあります。
データも流用しているので、フルチェックが伸びそうであればブロガーの本棚は終了する方向で考えています。
あと、前述の通りレコメンド機能は充実させる予定です。
どこのショッピングサイトにもついているレコメンド機能ですが、自分の経験上あまり新しい出会いにつながってる感じがしません。もっとディープに掘り下げられるようなレコメンドが可能なんじゃないかと考えてます。
レコメンド単体のサービスにしたほうがエッジが効いてていいかなとも思ったんですが、トラフィック分散させてもモチベーションに関わるので総合サイトとしての扱いになりました。
ちなみにレコメンド系は過去に「この人も好きかも(閉鎖済)」というのを運営してたことがあります。
さらに商品検索結果は画像大きめにしてレビューも一覧できるようにしました。これは今運営中の「一望amazon」を踏襲しています。
というわけで、これまで自分が作ってきたショッピング系サイトのコンセプトをまとめたような格好になってます。いままで自分なりに便利だと思うものを作ってはきたけどあんまりトラフィックが伸びなかったのでリベンジ的な意味合いもあります。以前よりはサイト開発運営のノウハウも深まっていますし。
いろいろ理念だけ先行していて機能的には未成熟な感じですが様子見しながらバージョンアップを重ねていければと思います。
どうぞご利用ください。
レビューとレコメンドの総合サイト「フルチェック」
http://flck.jp/